

A Survey of Big Data Streaming Engines
##Summary This article is intended to provide a brief survey of Big Data “Streaming” Technologies that are currently on the market for the purpose of informing and assisting customers in selecting the best streaming product for your problem. As this is a fairly large rapidly evolving space and what encompasses a “Streaming” product is somewhat subjective, the article does not intend to be all inclusive of every product available on the market. However, it should contain most of the major players within the Open Source space.
We also offer advice on factors you should consider when selecting a Streaming technology for your problem or solution. The ratings we include are OpenWhere’s opinion based on applicability to our customer’s common problems and missions around “general” high throughput low latency streaming problems. We hope you find this information informative but as always, do your due diligence and consider how each product rates for your specific requirements.
##Overview and Background The rapid growth of high velocity data streams such as Twitter and other social media sites, high traffic web pages, or live streaming events, has spawned the need for and development of high performance distributed technologies for rapidly ingesting and processing data in near real time. These “Streaming” big data technologies are often contrasted to traditional big data technologies such as Apache Hadoop, which can be described as operating in a “batch” or “offline” manner.
Technologies such as Hadoop are very good at answering large questions considering an entire data set at once. This is accomplished by partioning the problem (during the Map phase) and then later combining for a result via a reduction (Reduce phase of Map Reduce). These technologies are designed for scaling a process’s data storage horizontally across many servers and also try to collocate processing with the data to reduce network traffic. An example of a suitable problem for Hadoop would be computing a distribution by age or other factors for patients with a specific medical condition across a dataset of millions of medical records.
While batch solutions have very high throughput compared to traditional systems enabling them to solve these large and complex problems, these systems also often exhibit very high latency. For some problems, there are requirements that necessitate the computation of a result with very little latency (milliseconds or seconds) for which traditional batch big data solutions are not suitable. These problems also require high throughput beyond the performance of a single server and often the processing only needs to be done on a single record at a time or small batches of records.
These requirements drive the need for “Streaming” big data technologies. This space is still relatively immature and in active development. Many new players have been introduced into the market even within just the past few months as of the time of writing. It should also be noted that while many products can be considered to fit within this category, many of the new entrants are targeted at a specific problem within this subdomain such as Complex Event Processing (CEP). This assessment by OpenWhere represents our opinion on the most suitable technologies for solving “general” streaming problems that our customers often face within the GIS space by considering the options available at the time of writing. The requirements for solutions often include record ingest, transformation, processing, data analytics, and loading into a persistent store. Another requirement considered is the application’s suitability for running in the cloud. Primarily Open Source solutions were considered for this study due to customer demand.
##Streaming Requirement Considerations
When selecting a Streaming technology, there are many system factors or features enabled by the various products that you might need to consider and should be aware of when choosing a product suitable for your organization. These factors can be important based on your project requirements and it is often difficult to refactor later to another technology once one is adopted. As many of the products in this survey are Beta, they may later support these features in a future release. However, some factors are fundamental to the project’s architecture and design choices. Some important factors to consider are listed below:
Consider what specific requirements your have does the product provide the following?
- At Least Once and/or Exactly Once Semantics for message processing
- Exactly once is necessary for accurate counting
- Either is necessary for guaranteeing a message will be processed
- Fault Tolerance Guarantees and Approach
- Transactional data streams
- Committing and replaying of messages
- Message Batching
- Message Windowing
- (Built In / Possible via custom implementation)
- A high level Stream programming abstraction
- (Streams / Flows / Tuples / Events)
- Workflows or Frameworks for managing complex Streams or Event graphs
- State Management (high performance and collocated with processing)
- (Internal / External)
- Stream Aggregation, Partitioning, Routing & Grouping
- Message Ordering Guarantees
- Community Support, Examples, Libraries and Code Reuse
- Analytics support and packages available <br /> ##Streaming Performance & Management Considerations Not every Streaming product has the same performance characteristics for different data sets and processing needs due to differences in their architectures, approaches and philosophies. It should also be noted that it can be complex to deploy, monitor, and manage these complex distributed systems. Because many of these products are also immature, many don’t have the tooling support of traditional systems you might be accustomed to more mature products or from COTS vendors.
Consider the following performance factors when selecting a product:
- Message Throughput and horizontal scalability approach
- Does the product support or require partioning?
- Does the product enable multiple simultaneous streams?
- Processing Latency factors
- Does the system operate in memory (like Storm) or use persistence during message exchange (Kinesis, Samza, etc.)
- Horizontal and Stream Scaling Strategy
- Partitioning & Message Distribution Support
- Inter-node communication & backpressure
- Monitoring & Metrics Tools and Support
- Built In / Possible / None
- System Processing Isolation
- (None, JVM, Process, YARN, other)
- Stability / Replication / Fault Tolerance
- Cloud or EC2 integration or support <br /> ##Other Considerations There are also licensing, product maturity, and other factors worth considering.
Below are some additional factors: - Licensing Agreement Factors - Product Maturity and Stability - Growth Potential and Velocity of the Product - The product’s FOSS & SW Dependencies required - How easy it is to Install and is there existing DevOps Automation? - Security - API Exposure and cleanliness of Architecture - Product’s complexity and learning curve - Software Language support and requirements - Ease of integrating and how it compliments your existing environment
##Survey
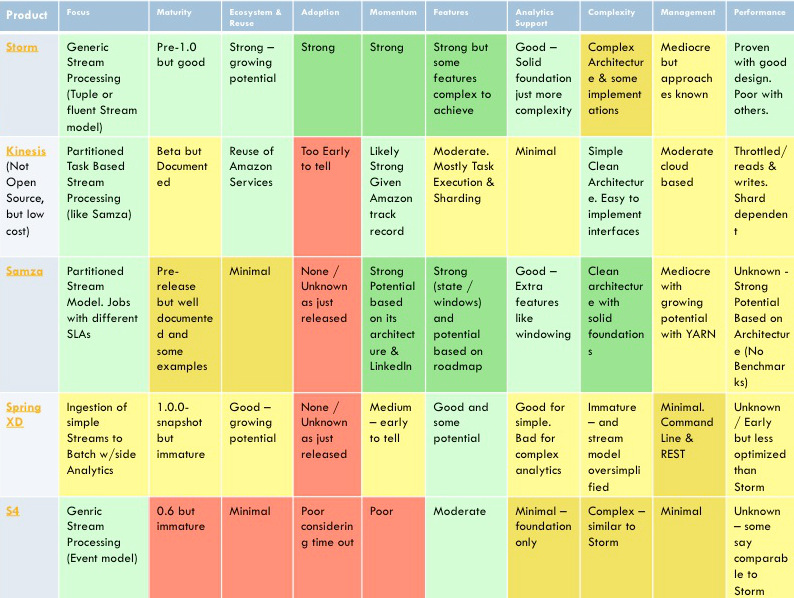 Big Data Streaming Engines
Big Data Streaming Engines
These products represent some of the core current players. Of the current products Storm currently has the widest adoption and is the most mature.
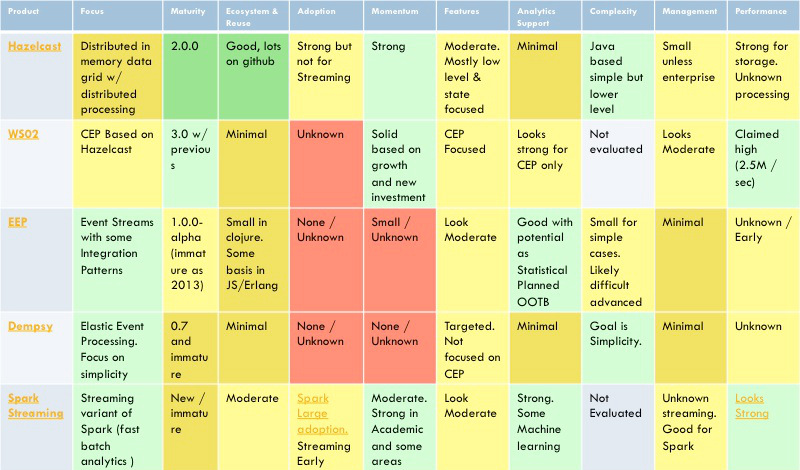 Additional Relevant Engines
Additional Relevant Engines
These are some additional products worth considering. Some of these products are more focused on specialized requirements.
##Recommendations Although still technically Beta, Storm is currently the most mature product available for general Stream processing. The product is currently in use and proven to scale at a large number of companies and government agencies. The product has also recently been adopted for Incubation under the Apache Foundation, which is another good sign for the product’s longevity. While the architecture is a bit complex and there is some learning curve involved (especially for more complex processing and how it does book keeping), it is pretty simple to get started with Storm and the product has the versatility to grow with your organization and use case.
However, if your processing flows are less complex (read, perform some operations, then write) and you operate in AWS or use any of the Amazon AWS services, Kinesis while still beta might be a very good alternative to consider due to its simplicity, ease of integration, and management within AWS.
Samza out of LinkedIn (the same Organization who made Kafka which many of these streaming products require) represents another promising alternative. Architectully it is less complex than Storm and it includes some interesting features out of the box. It’s use of YARN as a Resource manage (out of the next generation Hadoop ecosystem) will also likely be a significant strength for the product. However, Samza (also an Apache Incubator) is still beta without an official release version so it represents greater risk in its adoption.
If your problem is more specialized you might also want to consider some of the more specialized products listed below in this survey. For example look at Hazelcast if your needs are more suited toward an In-Memory-Datagrid or there are also several products more tightly focused on Complex Event Processing (CEP) which might warrant consideration.
##Links Project homepages for those looked at in this survey.